
In meinem https://www.addresults.de/artikel/kuenstliche-intelligenz.html Builder: letzten Artikel haben wir uns mit den grundlegenden Definitionen von künstlicher Intelligenz (KI), Machine Learning (ML) und Deep Learning (DL) auseinandergesetzt. In diesem Beitrag wollen wir einen beispielhaften Business Case bearbeiten, sodass wir auch ein wenig besser verstehen können, was die Probleme sind.
CRISP-DM Framework und Datenverständnis
Am Ende des Artikels finden Sie den verwendeten Python-Code zum Download. Ich ermutige Sie, sich den Code jeweils in den auskommentierten Abschnitten anzuschauen und zu verstehen, was die entsprechenden Ausgaben bewirken.
Vorstellung des Business Cases
Stellen wir uns vor, wir betreiben eine Bikesharing Firma, die Bicycle AG. Wir verleihen also zeitweise an unsere Kund*innen Fahrräder. Wir wollen besser vorhersagen können, zu welcher Uhrzeit, abhängig von Geodaten wie Wetter, Luftfeuchtigkeit etc., aber auch der Uhrzeit und dem Wochentag, wir wieviele Fahrräder zur Verfügung stellen müssten. Insbesondere wäre uns wichtig, dass die Entscheidung, sofern möglich, für einen Menschen gut nachvollziehbar ist.
Unter dem folgenden Link: https://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset und am Ende des Artikels finden Sie das Datenset, das wir an dieser Stelle verwenden. Generell können Sie sich die verlinkte Website als Quelle für gute und frei verfügbare Datensätze merken, wenn Sie gerne mit KI-Methoden experimentieren möchten.
In dem hier beschriebenen Fall, möchte ich mit Ihnen den stündlichen Datensatz anschauen. Also importieren wir die in dem Datenset enthaltene Datei hour.csv.
Vorstellung des CRISP-DM-Frameworks
{kind=link}
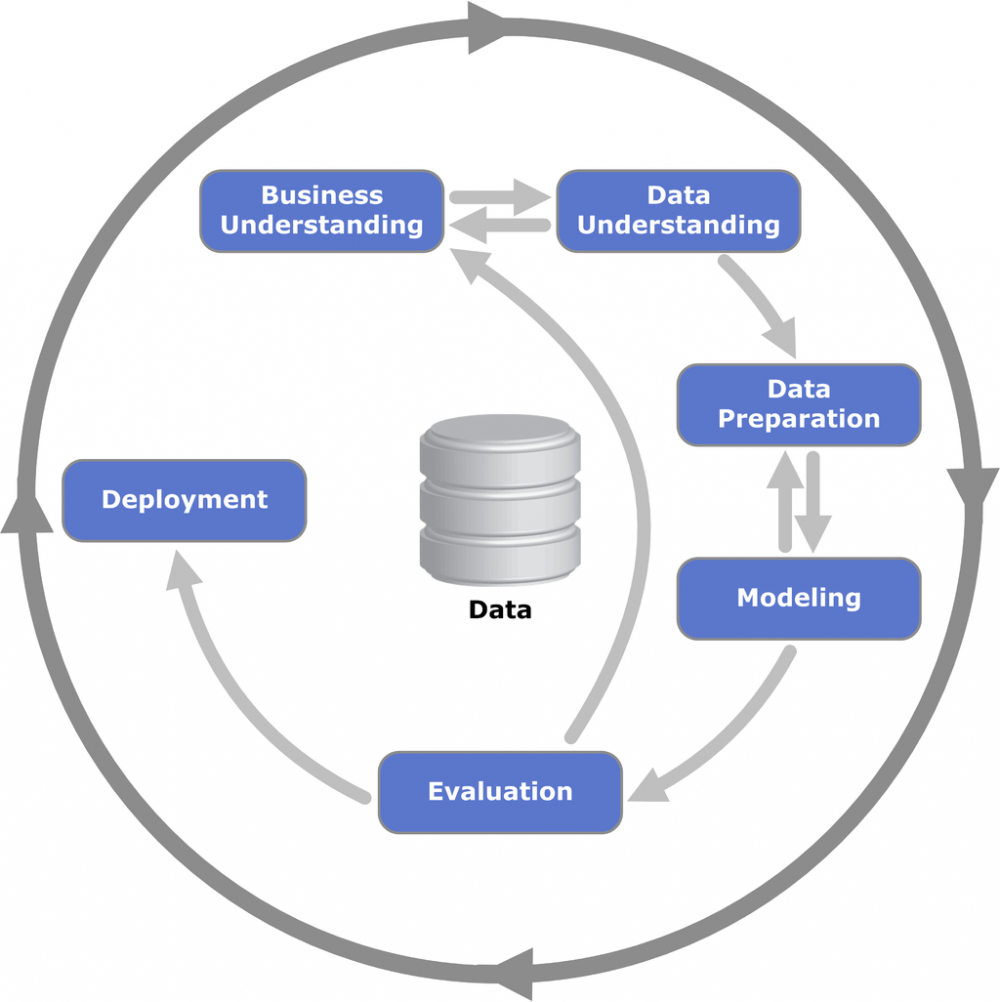
Das CRISP-DM Framework ist ein von der EU gefördertes Standardmodell für Data Mining, das bereits 1996 entwickelt wurde und bis heute als Grundlage für branchenübergreifende Projekte der künstlichen Intelligenz dient. Durch seine Anwendungsneutralität ist es vielseitig anwendbar und gibt einen einfachen, aber wirkungsvollen Leitfaden zur Entwicklung von KI-Prozessen. Wie ich bereits in meinem letzten Artikel beschrieben habe, sind hochwertige und genaue Daten eine Grundvoraussetzung für eine erfolgreiche Modellierung einer Klassifikationsaufgabe. Das CRISP-DM Framework erinnert sehr bildlich daran, dass wir die verschiedenen Phasen von Datenverständnis bis hin zur Evaluation, auch Validation genannt, möglicherweise sehr häufig durchlaufen müssen, um ein optimales Resultat zu erhalten.
Das CRISP-DM Framework wird durch sechs Phasen beschrieben:
Beim Business Understanding geht es darum, die Problemstellung genau zu verstehen. In unserem Fall geht es darum, die Anzahl der benötigten Fahrräder möglichst exakt vorherzusagen.
Das Data Understanding bezeichnet das Verständnis der vorliegenden Daten. Hierbei könnte man zum Beispiel den Einfluss der Variablen (oder Features, Attribute) auf den Output untersuchen. Aber auch die Untersuchung von Kovarianzen und Korrelationen innerhalb der Daten ist hierbei sehr wichtig.
Bei der Data Preparation geht es darum, die Daten so aufzubereiten, dass wir unsere Methoden gut anwenden können. Wie oben erwähnt, ist eine gute Datenqualität fundamental für den Erfolg – das ist so wichtig, man kann es nicht oft genug sagen.
Beim Modeling wird die Methode unter vielen Gesichtspunkten ausgewählt, auch die Wahl von Trainings- und Testdaten passiert hier. Aus fachwissenschaftlicher Perspektive passiert (meiner Meinung nach) in diesem und in dem vorherigen Schritt das Spannendste, denn hier benötigt man neben der Erfahrung auch sehr viel Know-how, gerade aus der Mathematik. Aber das ist auch der Teil, der entscheidend ist für den (Miss-)Erfolg des Projektes.
Bei der Evaluation wird der Erfolg der Methode gemessen. Bestimmte, vorher festgelegte Kenngrößen (wie Vorhersagegenauigkeit etc.) werden ausgewertet. Durch seine Interpretierbarkeit ist für das Management die Validation und Performancemessung eine entscheidende Einflussgröße.
Beim Deployment wird die vorher evaluierte Methode in den Geschäftsprozess integriert. Neben der Bereitstellung der Methode fällt auch das Schulen der Mitarbeiter*innen in diese Phase.
In diesem Artikel wollen wir uns mit den ersten beiden Phasen auseinandersetzen, dem Business Understanding (das haben wir bereits erledigt) und dem Data Understanding.
Data Understanding: Warum ist Statistik wichtig für KI-Methoden?
Wir möchten in diesem Schritt die vorliegenden Daten verstehen. Dazu müssen wir erstmal wissen, wie die Daten aussehen, daher hier ein kleiner Ausschnitt der Daten:

Wie man dem Inhalt des Datensatzes entnehmen kann, enthält dieser Datensatz Material über einen Zeitraum von zwei Jahren und insgesamt 16 Features. Ein Feature ist hierbei ein Merkmal, was den Output (also die Anzahl der benötigten Fahrräder) beeinflusst. Ein Feature ist in unserem Beispiel unter anderem die Außentemperatur, die gefühlte Temperatur oder auch die Uhrzeit.
Das erste Ziel ist: Wir möchten herausfinden, wie sich bestimmte Features auf den Output auswirken, Ausreißer finden und Korrelationen zwischen den einzelnen Features aufdecken.
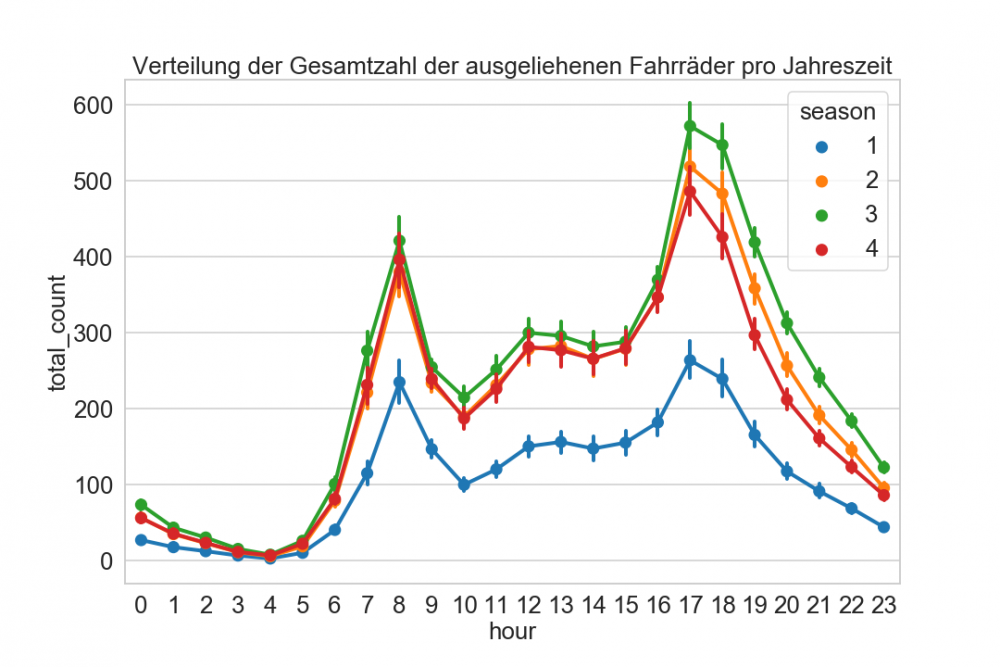
In der obigen Grafik haben wir pro Jahreszeit (1 = Winter, 2 = Frühling, 3 = Sommer, 4 = Herbst), abhängig von der jeweiligen Stunde, den Mittelwert der ausgeliehenen Fahrräder eingetragen. Ein wichtiger Schritt beim Datenverständnis ist, dass man versucht, die gefundenen Daten zu plausibilisieren. In unserem Fall haben wir zwei Hochpunkte: um 8 Uhr und um 17 Uhr. Dies könnte darauf schließen, dass unsere Kund*innen häufig unseren Service für den Arbeitsweg nutzen. Ebenfalls war zu erwarten, dass im Winter deutlich weniger Fahrräder ausgeliehen werden. Interessant ist ebenfalls, dass der Grundverlauf der einzelnen Kurven unabhängig von der Jahreszeit, sehr ähnlich aussieht. In dem bereitgestellten Pythonskript finden Sie noch weitere Auswertungen. Ich ermuntere Sie, sich diese genau anzuschauen und ggf. Unstimmigkeiten zu klären.
Die nachfolgende Grafik ist die Korrelationsmatrix der einzelnen Features zueinander:
Eine Korrelationsmatrix stellt die Abhängigkeit der einzelnen Feature zueinander genauer dar. Ein Beispiel: Die Korrelation zwischen temp und total_count, also der Außentemperatur und der Anzahl der benötigten Fahrräder, ist 0,4. Das bedeutet, je wärmer es wird, desto mehr Fahrräder werden tendenziell benötigt. Dies ist ein Zusammenhang, der für alle Leute durchaus nachvollziehbar ist.
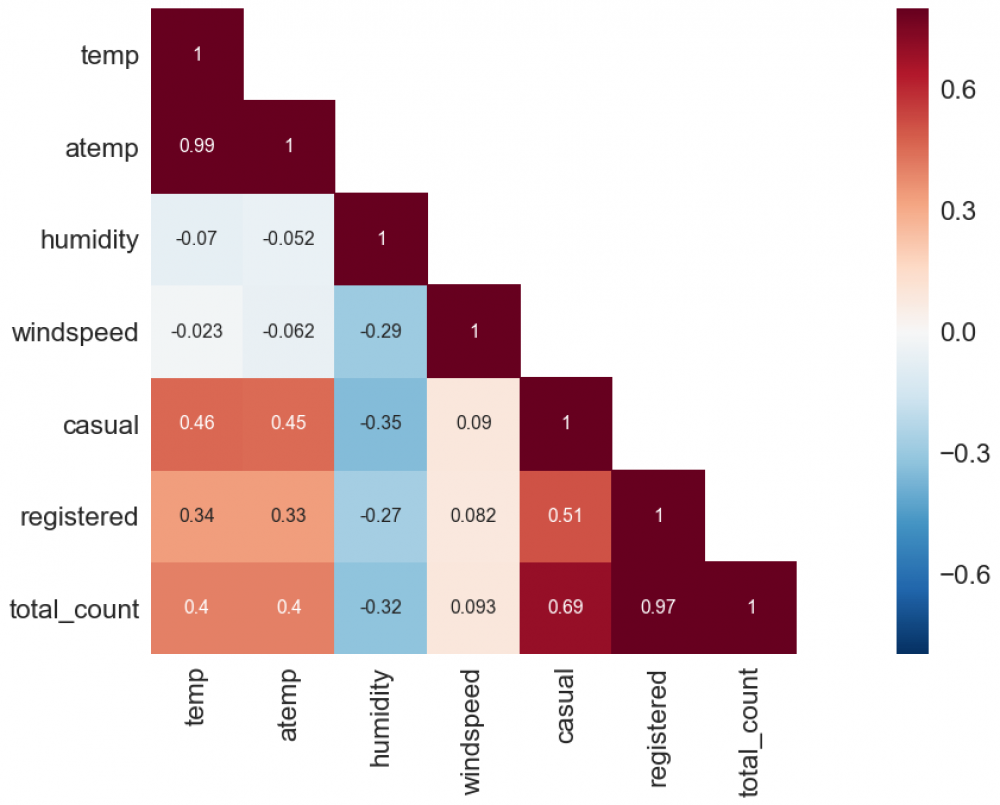

Da die Reihenfolge hier keine Rolle spielt, ist die Korrelationsmatrix eine symmetrische Matrix, weswegen die Einträge oberhalb der Diagonalen weggelassen werden. Grob gesprochen gibt diese Matrix an, wie sehr die einzelnen Feature sich gegenseitig beeinflussen.
Wir sehen, dass die gemessene und die gefühlte Außentemperatur (temp und atemp) sehr stark korrelieren, was wir auch durchaus erwarten würden. Wenn die Außentemperatur steigt, steigt genauso die gefühlte Temperatur. Auch unser Output (total_count) korreliert mit der Anzahl der registrierten Nutzer (registered) und den nicht-registrierten Nutzern (casual). Auch das macht Sinn: Je mehr registrierte Nutzer wir haben, desto mehr Fahrräder müssen wir bereitstellen.
Zusammenfassung
Die Analyse eines (anscheinend einfachen) Problems kann beliebig schwierig sein, wobei es hier auch darauf ankommt, wie tief man in die Analyse einsteigt. Wir haben das CRISP-DM Framework kennengelernt, mit dessen Hilfe es möglich ist, ein geplantes KI-Projekt sinnvoll zu strukturieren. Meiner Meinung nach, kann man nicht genug Zeit aufwenden, um die Daten zu verstehen und ggf. Zusammenhänge zu finden, die einem vielleicht später durchaus helfen können.
Wie Sie nachvollziehen können, ist die Entwicklung einer passenden KI-Methode mit viel Planungsaufwand verbunden und benötigt dazu sehr spezielles Know-how.
Literaturempfehlung
Eine Literaturempfehlung noch von mir: Das Buch „Practical Machine Learning with Python“ von Sarkar, Bali und Sharma. In diesem Buch werden sowohl theoretische Grundlagen als auch praktische Beispiele (der hier vorgestellte Business Case stammt aus diesem Buch) diskutiert und der Code online zur Verfügung gestellt. Wenn Sie also Interesse an der Thematik haben, so kann ich Ihnen dieses Fachbuch guten Gewissens ans Herz legen.