
Bereits im Jahre 2016 wurde der Begriff „FAKE NEWS“ zum Anglizismus des Jahres gewählt und ist heute nach wie vor von wichtiger Bedeutung. Die Verbreitung von falschen Informationen bildet mittlerweile einen ganzen Berufszweig, durch den aktiv in die Gesellschaft eingegriffen wird. Mit einem unscheinbaren Ansatz, kann auf die Probe gestellt werden, wer der wirkliche Urheber einer Nachricht ist.
Wer ist der wahre Urheber?
Es werden jeden Tag enorme Textmengen verfasst und veröffentlicht. Dieser Zustand sollte nicht weiter beunruhigen, denn schließlich sind wir es gewohnt, dass beinahe jede Kommunikation auf elektronischem Wege stattfindet.
Es gibt allerdings Bereiche, bei denen es zunehmend problematischer wird, nicht zu wissen, wer der eigentliche Urheber ist. Heutzutage ist es leichter denn je seine Identität hinter Pseudonymen zu verstecken und damit meinungsbildend in der Gesellschaft mitzuwirken.
Seien es Artikel in Printmedien, digitale Publikationen oder Kommentare in sozialen Netzwerken, der Begriff der „FAKE NEWS“ ist ein stetiger Begleiter in unserem Alltag und sorgt für eine zweifelhaften Ruf der Informationsverteilung. Die meisten Menschen bleiben ihrem Schreibstil dabei treu und genau diesen Zustand kann man ausnutzen, um den eigentlichen Autor zu entlarven.
Textanalyse zur Erkennung des Urhebers
Hat man nun eine Vermutung, dass der Urheber einer Menge von Publikationen identisch ist, so bereitet man zunächst die vorhandenen Texte vor und überführt sie, wie in meinem letzten Artikel beschrieben, in ein geeignetes Format. Somit transformieren wir die Datei in ein Dataframe, bestehend aus einem Wort pro Zeile. Nach der Bereinigung dieser Daten lässt sich leicht die Wortfrequenz bestimmen. Diese gibt an, in welcher relativen Häufigkeit ein Wort in einem Text vorkommt.
In diesem Kontext kommt mathematisch die Produkt-Moment-Korrelation nach dem Mathematiker Karl Pearson als ein sinnvolles Werkzeug ins Spiel. Der hier zum Tragen kommende Korrelationskoeffizient ist ein Maß für den Grad des linearen Zusammenhangs zwischen zwei Datenpaaren. Formal beschreibt man dies folgendermaßen:

Praxisbeispiel: Der Urheber wird analysiert
Für diese Fallstudie wurden die folgenden Reden als Datenquelle herangezogen: (AM1), (AM2) und (CL). Dieses Vorgehen lässt sich aber auch auf eine beliebige Anzahl von Dokumenten anwenden.
Als Ergebnis des Preprocessings hat man eine vollständige Übersicht über die Wortfrequenzen in allen Dokumenten und kann mit der Auswertung beginnen. Wie im letzten Eintrag bereits erwähnt, bemerkt man schnell, dass bestimmte Begriffe häufig in allen Quellen genutzt werden und es zeichnet sich auf den ersten Blick ab, dass eine Ähnlichkeit in der verwendeten Sprache besteht. Doch stellen wir es auf die Probe! Ohne weiter ins Detail zu gehen, nutze ich die in vielen Entwicklungsumgebungen integrierte Funktionalität Korrelationsberechnung. In der Programmiersprache R verwendet man dazu z.B. die Funktionen cor() oder cor.test() mit der Ausprägung pearson, um den Korrelationskoeffizienten nach Pearson zu berechnen.
Dieser Prozess bestimmt nun für uns den Korrelationskoeffizienten unter einem Konfidenzintervall von 95% und liefert folgende Ergebnisse:

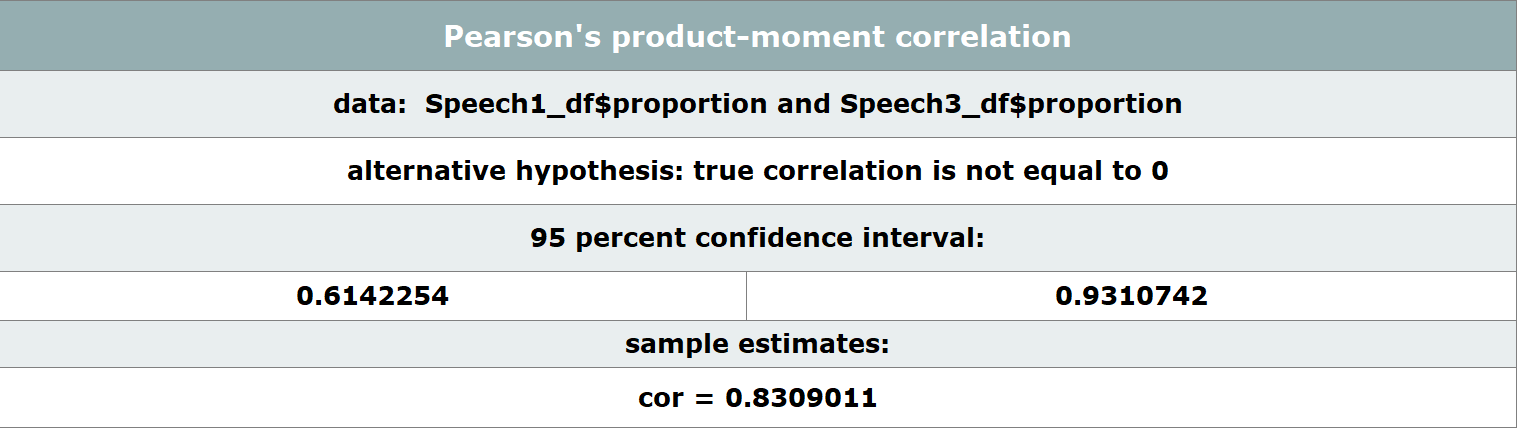
Zu unserem Erstaunen könnte das Ergebnis nicht eindeutiger sein. Unsere Vermutung wurde durch eine Korrelation von 1 bestätigt und wir können davon ausgehen, dass der Autor von (AM1) und (AM2) höchstwahrscheinlich identisch ist. Die untere Grafik zeigt eine Probe auf Korrelation von (AM1) und (CL) und weist einen deutlich niedrigeren Wert auf und deutet auf eine schwächere Ähnlichkeit hin.
Der Urheber kann mittels Textanalysemethoden erkannt werden
Abschließend ist zu sagen, dass es deutlich komplexere Analysemethoden für eine solche Thematik gibt, die wahrscheinlich aussagekräftigere Antworten liefern. Die gängigsten Methoden stellt das Natural Language Processing, ein Teilgebiet des maschinellen Lernens, bereit. Jedoch können statistische Methoden, wie die in diesem Artikel beschriebene, in ausreichender Präzision Aussagen treffen. Mit der zunehmenden Vernetzung unseres Informationsuniversums rückt eine solche Thematik immer weiter in den Mittelpunkt und kann maschinell, einer Streuung von Fehlinformationen, soweit gewollt, entgegenwirken.