
Viele Artikel zur Kölner Phonetik enden dort, wo es eigentlich interessant wird: bei der Beschreibung des Verfahrens. Was fast immer fehlt, ist die konsequente Umsetzung in einer Analyseplattform – nachvollziehbar, reproduzierbar und für Einsteiger begreifbar.
Dieser Exkurs geht weiter: Er zeigt, wie phonetische Logik sauber, reproduzierbar und nachvollziehbar in Power Query umgesetzt wird – ohne Blackbox und ohne implizite Entscheidungen.
Dieser Artikel ist Teil 4 unserer Serie über die Kölner Phonetik
- Teil 1 Warum exakte Daten analytisch falsch sein können
- Teil 2 Die Kölner Phonetik verstehen, nicht nur anwenden
- Teil 3 Kölner Phonetik mit Power Query umgesetzt in der Datenanalyse
- Teil 4 Die Kölner Phonetik in der Praxis: Code, Logik und Anwendung – ein methodischer Deep Dive für Einsteiger
Einstieg für Einsteiger: Wo beginnt man überhaupt?
Wer zum ersten Mal mit Power Query arbeitet, steht häufig vor der Frage, wo sich die eigentliche Logik verbirgt. Die gute Nachricht ist: Der Einstiegspunkt ist in Microsoft Excel und in Power BI praktisch identisch. In beiden Werkzeugen führt der Weg über den Power-Query-Editor – unabhängig davon, ob später mit Excel-Tabellen oder mit einem Power-BI-Datenmodell gearbeitet wird.
In Excel erfolgt der Zugriff über den Menüpunkt Daten und den Bereich Abfragen und Verbindungen. Jede dort vorhandene Abfrage lässt sich per Doppelklick öffnen. In Power BI Desktop führt der Weg über Start und den Befehl Transformieren direkt in den Power-Query-Editor. In beiden Fällen landet man in derselben Umgebung, mit denselben Funktionen und derselben zugrunde liegenden Logik.
Entscheidend für das Verständnis ist der sogenannte Erweiterte Editor. Er ist kein Spezialwerkzeug für Entwickler und auch kein „Expertenmodus“, sondern lediglich die textuelle Darstellung dessen, was Power Query ohnehin im Hintergrund ausführt. Jeder Klick im grafischen Benutzerinterface – sei es das Umbenennen einer Spalte, das Filtern von Zeilen oder das Hinzufügen einer Berechnung – erzeugt automatisch M-Code. Der Erweiterte Editor macht diesen Code sichtbar.
Für Einsteiger ist das ein wichtiger Perspektivwechsel. Wer den M-Code liest, versteht nicht nur, dass eine Transformation stattfindet, sondern was dabei konkret geschieht. Power Query wird damit von einem Klickwerkzeug zu einer nachvollziehbaren, dokumentierbaren Transformationslogik. Genau an dieser Stelle beginnt der bewusste Umgang mit Datenvorbereitung – und damit auch die saubere Umsetzung von Verfahren wie der Kölner Phonetik.
Architektur der Lösung – warum sie so aufgebaut ist
Bevor auf den eigentlichen Code eingegangen wird, lohnt sich ein Blick auf die grundlegende Architektur der Lösung. Denn die Art und Weise, wie die Kölner Phonetik in Power Query eingebettet wird, ist keine technische Nebensache, sondern eine bewusste methodische Entscheidung. Die Lösung folgt einer klaren Trennung zwischen Daten, Logik, Anwendung und Analyse.
Zunächst stehen die Daten selbst im Mittelpunkt: Beispieldaten, Tokenlisten oder freie Texte, die unverändert aus ihren Quellen übernommen werden. Sie bilden die fachliche Grundlage und bleiben jederzeit nachvollziehbar. Davon strikt getrennt ist die Logik der Kölner Phonetik. Sie wird nicht verteilt über mehrere Abfragen oder versteckt in einzelnen Transformationsschritten, sondern als eigenständige Power-Query-Funktion umgesetzt. Diese Funktion kapselt die gesamte phonetische Logik an einer zentralen Stelle.
Die Anwendung dieser Logik erfolgt anschließend bewusst separat. Der Phonetikcode wird als zusätzliche Spalte ergänzt, ohne die Originaldaten zu verändern oder zu überschreiben. Damit bleibt transparent, wie das Analyseergebnis zustande kommt. Erst auf dieser Basis folgt der analytische Teil: Sortierungen, Gruppierungen und Aggregationen, die den Effekt der phonetischen Normalisierung sichtbar machen.
Diese Trennung ist didaktisch zentral. Einsteiger lernen dabei implizit eine wichtige Grundregel der Datenanalyse: Fachliche Logik gehört nicht in Visualisierungen, sondern in klar definierte Funktionen. Die Kölner Phonetik ist deshalb kein Inline-Code innerhalb einer einzelnen Abfrage und kein einmaliges Skript, sondern eine wiederverwendbare, dokumentierte Funktion. Genau diese Architektur macht die Lösung nachvollziehbar, wartbar und für weitere Analysen anschlussfähig.
Für den schnellen Leser geht es hier direkt zu den bereitgestellten Dateien.
Die Phasen der Lösung – fachlicher Ablauf
Die Verarbeitung der Kölner Phonetik folgt keinem technischen Zufall, sondern einer klaren, logisch aufgebauten Abfolge von Phasen. Jede Phase erfüllt einen eigenen Zweck und baut bewusst auf der vorherigen auf. Erst diese Struktur macht das Verfahren verständlich, reproduzierbar und analytisch belastbar.
Der Ablauf beginnt bei den Rohdaten, führt über eine klar abgegrenzte Logikschicht und endet erst in der eigentlichen Analyse. Entscheidend ist dabei: Die phonetische Logik ist kein Analyseergebnis, sondern eine vorgelagerte Interpretationsregel.

Phase 1: Normalisierung – erst vergleichbar machen, dann vergleichen
Bevor überhaupt analysiert werden kann, müssen Eingaben vergleichbar sein. In realen Datenbeständen ist das fast nie der Fall. Namen, Begriffe oder Texte liegen in unterschiedlichster Form vor: mit wechselnder Groß- und Kleinschreibung, mit Umlauten oder deren Umschreibungen, mit Sonderzeichen, zusätzlichen Leerstellen oder Mischformen aus all dem. Formal sind diese Varianten korrekt, fachlich beschreiben sie jedoch häufig dasselbe.
Die Kölner Phonetik setzt genau an dieser Stelle an und trifft eine bewusste methodische Entscheidung: Sie vereinheitlicht die Schreibweise der Eingaben, bevor irgendeine Form von Vergleich oder Kodierung stattfindet. Das geschieht nicht aus Bequemlichkeit, sondern aus fachlicher Konsequenz. Solange Eingaben nicht auf eine gemeinsame, stabile Form gebracht wurden, ist jeder weitere Schritt analytisch fragwürdig.
Im Power-Query-Code wirkt dieser Schritt auf den ersten Blick unscheinbar. Zunächst werden überflüssige Leerstellen entfernt und alle Zeichen in Großbuchstaben überführt:
_upper = Text.Upper(Text.Trim(input))Etwas später folgt die gezielte Vereinheitlichung von Umlauten und Sonderzeichen:
_replaced =
Text.Replace(
Text.Replace(
Text.Replace(
Text.Replace(_upper, "Ä", "A"), "Ö", "O"),
"Ü", "U"),
"ß", "SS")Entscheidend ist hier nicht die konkrete Syntax, sondern die fachliche Entscheidung, die sich darin widerspiegelt. Alles, was den Klang nicht unterscheidet, wird vereinheitlicht. Unterschiede, die lediglich orthografisch oder technisch bedingt sind, sollen im weiteren Verlauf keine Rolle mehr spielen.
Erst durch diese Normalisierung wird aus „Müller“, „Mueller“ und „Möller“ überhaupt etwas Vergleichbares. Ohne diesen Schritt würde der Algorithmus später zwar formal korrekt arbeiten, aber auf einer instabilen Grundlage. Die Analyse wäre präzise, aber inhaltlich verzerrt.
Dieser Punkt ist zentral: Analyse beginnt nicht mit Berechnungen oder Aggregationen, sondern mit der Interpretation dessen, was als relevant gilt. Die Normalisierung ist deshalb kein technischer Nebenschritt, sondern die erste fachliche Entscheidung im gesamten Analyseprozess.
Die folgende Tabelle zeigt, wie unterschiedliche Schreibweisen durch Normalisierung zunächst technisch und fachlich vergleichbar gemacht werden.

Phase 2: Phonetische Kodierung – Buchstaben werden zu Lautklassen
Nach der Normalisierung liegen die Eingaben in einer vergleichbaren Form vor. Schreibvarianten, Umlaute und Sonderzeichen sind vereinheitlicht, irrelevante Unterschiede entfernt. Erst jetzt kann der eigentliche Kern der Kölner Phonetik greifen: die phonetische Kodierung.
In dieser Phase werden die einzelnen Buchstaben nicht mehr als Zeichen verstanden, sondern als Repräsentanten von Lauten. Ziel ist es, aus der orthografischen Darstellung eine lautliche Struktur abzuleiten. Entscheidend ist dabei nicht, wie ein Buchstabe geschrieben wird, sondern wie er im Wortkontext klingt.
Die Kölner Phonetik arbeitet hier bewusst regelbasiert. Jeder Buchstabe wird anhand fester Regeln einer sogenannten Lautklasse zugeordnet, die durch eine Ziffer repräsentiert wird. Vokale werden dabei grundsätzlich anders behandelt als Konsonanten. Viele Konsonanten werden zu Gruppen zusammengefasst, wenn sie phonetisch ähnlich klingen.
Im Code zeigt sich diese Logik in der zentralen Entscheidungsstruktur der Funktion. Vereinfacht beginnt sie mit der grundlegenden Unterscheidung zwischen Vokalen und Konsonanten:
isVowel = (c as text) as logical =>
List.Contains({"A","E","I","J","O","U","Y"}, c)Vokale werden zunächst mit dem Code „0“ belegt. Sie sind für den Klang zwar relevant, spielen aber in der späteren Stabilisierung nur eine untergeordnete Rolle. Konsonanten hingegen tragen den Großteil der lautlichen Information und werden differenziert behandelt.
Die eigentliche Kodierung erfolgt zeichenweise. Für jedes Zeichen wird geprüft, welcher Lautklasse es angehört. Einige Beispiele aus dem Regelwerk verdeutlichen das Prinzip:
else if List.Contains({"M","N"}, c) then "6"
else if c = "L" then "5"
else if c = "R" then "7"
else if List.Contains({"S","Z"}, c) then "8"Hier werden Buchstaben nicht einzeln betrachtet, sondern als Vertreter einer phonetischen Gruppe. „M“ und „N“ klingen in vielen Kontexten ähnlich und erhalten deshalb denselben Code. Gleiches gilt für andere Lautpaare oder -gruppen.
Besonders wichtig ist, dass die Kölner Phonetik nicht nur isolierte Buchstaben betrachtet, sondern deren Kontext einbezieht. Einige Buchstaben verändern ihren Klang abhängig davon, welche Zeichen davor oder danach stehen. Genau deshalb ermittelt der Code explizit den vorherigen und den nächsten Buchstaben:
prevChar = (i as number) as text =>
if i > 0 then chars{i - 1} else ""
nextChar = (i as number) as text =>
if i < len - 1 then chars{i + 1} else ""Diese Kontextinformation ist entscheidend für eine korrekte phonetische Abbildung. Besonders deutlich wird das bei Buchstaben wie „C“ oder „X“, deren Aussprache stark vom Umfeld abhängt. Der Algorithmus trifft hier differenzierte Entscheidungen, anstatt pauschale Zuordnungen vorzunehmen:
else if c = "C" then
let
nIn = List.Contains({"A","H","K","L","O","Q","R","U","X"}, n),
pSZ = List.Contains({"S","Z"}, p),
ccode = if nIn and (not pSZ) then "4" else "8"
in
ccodeDiese Logik wirkt auf den ersten Blick komplex, ist aber methodisch konsequent. Sie sorgt dafür, dass der Klang und nicht die Schreibweise im Mittelpunkt steht. Genau hier unterscheidet sich die Kölner Phonetik von vereinfachten Ansätzen, die Buchstaben starr einer Zahl zuordnen.
Das Ergebnis dieser Phase ist noch kein stabiler Phonetikcode, sondern eine Abfolge von Ziffern, die die Lautstruktur des Wortes abbildet. Diese Abfolge kann Wiederholungen enthalten, Vokalcodes einschließen und ist bewusst noch roh. Sie bildet die Grundlage für den nächsten Schritt, in dem diese Lautfolge reduziert und stabilisiert wird.
Phonetik ist also keine Statistik und kein Näherungsverfahren. Es ist eine explizite, nachvollziehbare Übersetzung von Sprache in Regeln. Jeder Code entsteht aus klar definierten Entscheidungen – und genau diese Transparenz macht die Methode analytisch belastbar.
Die folgende Tabelle verdeutlicht, wie Buchstaben in lautliche Klassen überführt werden.

Phase 3: Reduktion und Stabilisierung – aus Lautfolgen wird Analysefähigkeit
Nach der phonetischen Kodierung liegt das Wort nicht mehr als Text, sondern als Folge von Lautklassen vor. Diese Folge bildet den Klang ab, ist aber noch nicht stabil genug, um als analytisches Merkmal zu dienen. Sie enthält Wiederholungen, Vokalcodes und Konstellationen, die zwar phonetisch korrekt, analytisch jedoch redundant sind.
Die dritte Phase der Kölner Phonetik setzt genau hier an. Ihr Ziel ist es nicht, weitere Information hinzuzufügen, sondern gezielt Information zu entfernen – ohne den Klangcharakter zu verfälschen. Reduktion ist hier kein Verlust, sondern eine bewusste Verdichtung.
Der erste Schritt besteht darin, aufeinanderfolgende identische Lautcodes zusammenzufassen. Phonetisch ist es unerheblich, ob ein Laut einmal oder mehrfach hintereinander auftritt. Für die Analyse würde diese Wiederholung jedoch künstliche Unterschiede erzeugen. Deshalb werden doppelte Codes eliminiert.
Im Code geschieht dies über einen positionsabhängigen Vergleich der erzeugten Ziffernfolge:
dedup =
List.Transform(
{0..List.Count(rawDigits)-1},
(i) =>
if i = 0 then rawDigits{i}
else if rawDigits{i} = rawDigits{i-1} then null
else rawDigits{i}
)Hier zeigt sich ein zentrales Prinzip der
Kölner Phonetik:
Nicht jeder berechnete Wert ist relevant. Entscheidend ist, welche Unterschiede
für den Klang tatsächlich eine Rolle spielen.
Nach der Entfernung doppelter Lautfolgen folgt der zweite Stabilisierungsschritt: die Behandlung der Vokale. Vokale werden im Rahmen der Kölner Phonetik zwar erkannt, verlieren aber nach der Kodierung weitgehend ihre Bedeutung. Sie dienen primär der Strukturierung am Wortanfang, nicht der Unterscheidung innerhalb des Wortes.
Entsprechend werden alle Vokalcodes („0“) entfernt – mit einer einzigen Ausnahme: der erste Code bleibt erhalten. Dieser kann relevant sein, um den Wortanfang zu unterscheiden.
Im Code ist diese Entscheidung klar und explizit umgesetzt:
head = dedupClean{0}
tail = List.Skip(dedupClean, 1)
tailNoZeros = List.RemoveItems(tail, {"0"})
rebuilt = {head} & tailNoZerosDas Ergebnis dieser beiden Schritte ist eine deutlich verkürzte, aber stabile Ziffernfolge. Sie enthält nur noch die Informationen, die für den Klangunterschied wesentlich sind. Alles andere wurde bewusst entfernt.
Am Ende wird diese Lautfolge zu einem kompakten Phonetikcode zusammengeführt:
result = Text.Combine(finalDigits, "")Damit ist die Transformation abgeschlossen. Aus einem ursprünglich vieldeutigen Textwert ist ein deterministischer, reproduzierbarer Code entstanden, der als analytisches Merkmal verwendet werden kann.
Der entscheidende Punkt dieser Phase liegt nicht in der technischen Umsetzung, sondern in der methodischen Haltung:
Analyse braucht stabile Vergleichswerte. Diese Stabilität entsteht nicht durch zusätzliche Logik, sondern durch konsequente Reduktion auf das Wesentliche.
Erst durch diese Stabilisierung wird der Phonetikcode geeignet für Gruppierungen, Zählungen und Aggregationen. Die eigentliche Analyse beginnt damit erst im nächsten Schritt – wenn der Code nicht mehr berechnet, sondern angewendet wird.
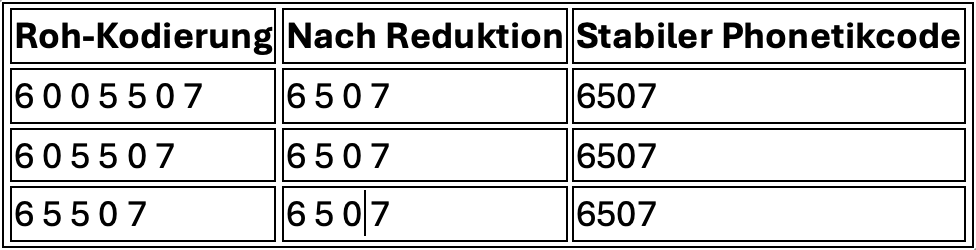
Die folgende Tabelle zeigt, wie aus einer rohen Lautfolge ein stabiler Phonetikcode entsteht.
Phase 4: Anwendung – Phonetik wird Teil der Datenstruktur
Mit Abschluss der Reduktion und Stabilisierung liegt ein belastbarer Phonetikcode vor. Bis hierhin war der gesamte Prozess algorithmisch geprägt: Zeichen wurden normalisiert, lautlich interpretiert und zu einer stabilen Repräsentation verdichtet. Doch erst in der Anwendung entscheidet sich, ob dieser Code analytisch tatsächlich einen Mehrwert liefert.
Die zentrale methodische Entscheidung dieser Phase lautet:
Der Phonetikcode ist kein Analyseergebnis, sondern ein zusätzliches Datenmerkmal. Er ersetzt keine bestehenden Felder, sondern ergänzt sie. Genau deshalb wird er in Power Query als eigene Spalte erzeugt – nicht als Measure, nicht als Visualisierungslogik und nicht als nachträgliche Berechnung im Reporting.
Im Code zeigt sich diese Entscheidung sehr klar. Die zuvor definierte Phonetik-Funktion wird auf eine bestehende Textspalte angewendet und erzeugt eine neue, explizite Spalte:
Table.AddColumn(
Quelle,
"Phonetik",
each KoelnerPhonetik([Text]),
type text
)Dieser Schritt ist technisch unspektakulär, methodisch jedoch zentral. Die Originaldaten bleiben unverändert erhalten. Der Phonetikcode steht gleichberechtigt daneben. Dadurch bleibt jederzeit nachvollziehbar, welcher Originalwert zu welchem Code geführt hat. Analyse wird transparent, nicht verdeckt.
Mit dieser Spalte verschiebt sich die Perspektive auf die Daten. Während zuvor unterschiedliche Schreibweisen zwangsläufig als unterschiedliche Werte behandelt wurden, entsteht nun eine zusätzliche Ebene, auf der fachlich zusammengehörige Einträge sichtbar werden. Schreibvarianten, Umlaute oder leichte Abweichungen verlieren ihre trennende Wirkung.
Entscheidend ist, dass diese Anwendung nicht auf einzelne Beispiele beschränkt bleibt. Die Funktion wird systematisch auf ganze Tabellen angewendet – auf freie Texte ebenso wie auf kontrollierte Tokenlisten. Damit wird Phonetik zu einem strukturellen Bestandteil der Datenbasis, nicht zu einem punktuellen Hilfsmittel.
In der Praxis zeigt sich der Effekt sofort:
Daten, die zuvor fragmentiert wirkten, beginnen sich zu gruppieren. Wiederkehrende Muster werden sichtbar. Häufigkeiten stabilisieren sich. Analysen, die zuvor scheinbar inkonsistent waren, lassen sich plötzlich schlüssig erklären.
Wichtig ist dabei, was nicht passiert:
Es findet keine automatische „Bereinigung“ statt, keine Zusammenführung von Datensätzen, keine verdeckte Dublettenauflösung. Die Anwendung der Phonetik erzeugt lediglich eine neue Sicht auf die Daten. Welche Konsequenzen daraus gezogen werden, bleibt eine fachliche Entscheidung und kein automatischer Prozess.
Genau diese Trennung macht den Ansatz robust. Die Phonetik liefert eine zusätzliche Interpretationsdimension, aber sie erzwingt keine fachlichen Schlüsse. Sie ermöglicht Analyse, ersetzt sie aber nicht.
Mit Abschluss dieser Phase ist der Algorithmus vollständig in die Datenstruktur integriert. Ab jetzt geht es nicht mehr um Berechnung, sondern um Auswertung. Gruppierungen, Aggregationen und Vergleiche nutzen den Phonetikcode als stabiles Merkmal – und genau dort entfaltet sich sein analytischer Nutzen.
Die folgende Tabelle zeigt, wie der Phonetikcode als zusätzliches Merkmal in die Datenstruktur integriert wird.

Phase 5: Analyse und Aggregation – wenn Klang zu Struktur wird
Mit der Anwendung des Phonetikcodes ist die eigentliche Voraussetzung für Analyse geschaffen. Erst jetzt liegt eine Datenstruktur vor, die fachlich vergleichbar ist. Die Unterschiede, die zuvor ausschließlich aus Schreibvarianten resultierten, sind nicht verschwunden, aber sie dominieren die Analyse nicht mehr. Stattdessen tritt eine neue Ordnungsebene hinzu, die den Klang als strukturierendes Merkmal nutzt.
In der Analyse zeigt sich dieser Effekt besonders deutlich bei Gruppierungen und Aggregationen. Während klassische Auswertungen auf der ursprünglichen Textspalte zwangsläufig viele kleine, scheinbar unterschiedliche Gruppen erzeugen, führt die Gruppierung nach dem Phonetikcode zu einer deutlich stabileren Struktur. Varianten, die fachlich zusammengehören, werden gemeinsam betrachtet.
Technisch wird dieser Schritt in Power Query über Gruppierungsoperationen umgesetzt. Der Phonetikcode fungiert dabei als Gruppierungsschlüssel, während weitere Kennzahlen oder Beispielwerte aggregiert werden:
Table.Group(
src,
{"Phonetik"},
{
{"Anzahl", each Table.RowCount(_), Int64.Type},
{"Beispiele", each Text.Combine(List.FirstN(List.Distinct([Text]), 5), " | "), type text}
}
)Diese Aggregation ist bewusst einfach gehalten. Sie zählt nicht nur, wie häufig ein Phonetikcode vorkommt, sondern zeigt exemplarisch, welche ursprünglichen Texte oder Schreibweisen dahinterstehen. Genau diese Kombination aus Quantität und Kontext ist analytisch wertvoll. Sie verhindert, dass der Code zu einer abstrakten Zahl ohne Bezug zur Realität wird.
In der Praxis offenbaren solche Aggregationen Muster, die zuvor verborgen waren. Häufig zeigt sich, dass ein erheblicher Anteil der vermeintlichen Vielfalt in den Daten auf wenige phonetische Kerne zurückzuführen ist. Unterschiede, die zuvor als fachlich relevant erschienen, entpuppen sich als reine Darstellungsvarianten.
Ein weiterer wichtiger Schritt ist die Kreuzung des Phonetikcodes mit fachlichen Attributen. Wird der Code beispielsweise mit Kategorien, Gruppen oder Herkunftsmerkmalen kombiniert, entstehen neue analytische Perspektiven. Phonetische Cluster lassen sich in fachliche Kontexte einordnen, ohne dass die zugrunde liegenden Texte manuell bereinigt werden müssen.
Solche Kreuztabellen zeigen, dass Phonetik nicht isoliert wirkt, sondern bestehende Analysen stabilisiert. Sie reduziert Rauschen, ohne Information zu vernichten. Unterschiede bleiben sichtbar, aber sie werden in einen sinnvollen Zusammenhang gestellt.
Entscheidend ist auch hier die methodische Zurückhaltung. Die Aggregation nach Phonetikcode ist kein Automatismus zur Zusammenführung von Daten. Sie ist eine analytische Sichtweise, die bewusst gewählt wird. Je nach Fragestellung kann sie genutzt oder bewusst ignoriert werden. Genau diese Wahlmöglichkeit macht den Ansatz kontrollierbar und nachvollziehbar.
In Berichten oder Dashboards wird dieser Effekt besonders deutlich. Kennzahlen, die zuvor schwankten oder schwer erklärbar waren, stabilisieren sich. Trends werden klarer. Auffälligkeiten lassen sich besser begründen, weil die zugrunde liegende Struktur konsistenter ist.
Mit Abschluss dieser Phase ist die Kölner Phonetik vollständig in die Analyse integriert. Sie wirkt nicht als Zusatzlogik, sondern als strukturierendes Element, das fachliche Interpretation unterstützt. Was folgt, ist keine weitere technische Vertiefung, sondern eine Einordnung: Welche Konsequenzen hat dieser Ansatz für Datenanalyse, Verantwortung und methodische Sauberkeit?
Die folgende Tabelle verdeutlicht den Effekt der phonetischen Gruppierung auf Aggregationen und Kennzahlen.

Phase 6: Einordnung – Analyse beginnt mit Interpretation
Die Kölner Phonetik ist kein Spezialverfahren für Randfälle und kein technisches Mittel zur Reparatur fehlerhafter Daten. Sie macht vielmehr sichtbar, dass jede Analyse auf grundlegenden Annahmen beruht. Eine der zentralen Fragen lautet dabei: Wann gelten zwei Werte als gleich?
In vielen Analysen bleibt diese Frage unbeachtet. Gleichheit wird implizit auf Zeichenebene definiert: Was identisch geschrieben ist, gilt als gleich, alles andere als verschieden. Diese Entscheidung ist technisch naheliegend, fachlich jedoch oft unzureichend – insbesondere bei sprachlichen Daten, deren Darstellung zwangsläufig variiert.
Die Kölner Phonetik verschiebt diese Gleichheitsannahme bewusst vom Schriftbild auf den Klang. Damit verändert sich nicht nur die Gruppierung der Daten, sondern ihre Interpretation. Schreibvarianten verlieren ihre trennende Wirkung, ohne unsichtbar zu werden. Sie bleiben erhalten, dominieren die Analyse jedoch nicht mehr.
Methodisch entscheidend ist, dass diese Logik nicht im Reporting versteckt wird. Die Phonetik ist Teil der Datenvorbereitung. Dort wird festgelegt, wie Daten gelesen und interpretiert werden. Visualisierungen zeigen anschließend die Ergebnisse dieser Entscheidungen, sie treffen sie nicht selbst.
Diese Trennung ist keine technische Formalität, sondern eine Frage analytischer Verantwortung. Analysen sind nur dann nachvollziehbar, wenn klar ist, welche Interpretationsregeln ihnen zugrunde liegen. Werden diese Regeln implizit oder verstreut umgesetzt, entziehen sie sich der Überprüfbarkeit. Werden sie explizit in der Datenstruktur verankert, bleiben sie transparent.
In diesem Sinne ist die Kölner Phonetik weniger ein Algorithmus als ein methodisches Statement. Sie erinnert daran, dass Analyse nicht mit Zahlen beginnt, sondern mit Interpretation – und dass gute Analyse dort ansetzt, wo diese Interpretation sichtbar gemacht wird: in der Datenvorbereitung.
Die folgende Tabelle stellt die methodischen Konsequenzen unterschiedlicher Gleichheitsannahmen gegenüber.

Zusammenfassung der Artikelreihe
Die Kölner Phonetik bietet hierfür keinen Ersatz für Datenqualität, sondern eine methodische Ergänzung. Sie übersetzt sprachliche Varianten systematisch in eine stabile, lautbasierte Repräsentation. Entscheidend ist dabei nicht der Algorithmus allein, sondern seine konsequente Einbettung in die Datenvorbereitung. Phonetik wird nicht als Analyseergebnis verstanden, sondern als Interpretationsregel, die vor jeder Aggregation greift.
Anhand der einzelnen Phasen – von der Normalisierung über die phonetische Kodierung und Stabilisierung bis hin zur Anwendung und Aggregation – wurde deutlich, wie aus Text zunächst Struktur entsteht und daraus belastbare Analysefähigkeit. Die Umsetzung in Power Query macht diese Logik transparent, reproduzierbar und unabhängig von der späteren Darstellung im Reporting.
Damit steht die Kölner Phonetik exemplarisch für eine grundsätzliche Haltung in der Datenanalyse: Gute Analysen beginnen nicht mit Visualisierungen oder Kennzahlen, sondern mit expliziten Entscheidungen darüber, wie Daten gelesen und interpretiert werden.
Was neben den Informationen geliefert wird – Artefakte und Quellcode
Die im Artikel beschriebene Lösung wird nicht nur konzeptionell erläutert, sondern vollständig nachvollziehbar bereitgestellt. Ziel ist es, den beschriebenen Ansatz nicht nur theoretisch zu verstehen, sondern selbst anzuwenden, zu prüfen und weiterzuverwenden.
Konkret werden folgende Artefakte zur Verfügung gestellt:
1. Vollständiger Power-Query-Quellcode (M-Code)
Der im Beitrag erläuterte Algorithmus zur Kölner Phonetik wird als vollständige, lauffähige Power-Query-Funktion bereitgestellt.
Der Code entspricht exakt der im Text beschriebenen Logik und ist durch CHATGPT 5.2 kommentiert, ohne die Funktionalität zu verändern. Er kann direkt in Power Query oder Power BI übernommen und in eigenen Projekten verwendet werden.
2. Beispieldaten zur Nachvollziehbarkeit
Ergänzend werden strukturierte Beispieldaten geliefert, die typische Schreibvarianten, Namen und Texte enthalten. Diese Daten dienen dazu, die einzelnen Phasen – Normalisierung, Kodierung, Reduktion und Aggregation – Schritt für Schritt nachzuvollziehen.
3. Anwendungsabfragen und Analysebeispiele in Power BI
Neben der reinen Funktion werden Beispielabfragen bereitgestellt, die zeigen, wie der Phonetikcode auf Daten angewendet und anschließend für Gruppierungen und Aggregationen genutzt wird. Damit wird der Übergang vom Algorithmus zur Analyse konkret nachvollziehbar.