
Vor einiger Zeit wurde ich zu einer Vortragsreihe zum Thema Internal Audit eingeladen. In jedem Vortrag kam zur Sprache, wie künstliche Intelligenz (KI) in Unternehmen zielführend eingesetzt werden kann. Ein sehr wichtiges Thema natürlich. Allerdings habe ich dabei gemerkt, wie inflationär und teilweise falsche Begrifflichkeiten aus dem Bereich der künstlichen Intelligenz verwendet worden sind.
Künstliche Intelligenz und Machine Learning: Dasselbe oder doch unterschiedlich?
Wie es für mich als Mathematiker üblich ist, wird es in diesem ersten Artikel zunächst um grundlegende Definitionen und Beispiele zu diesem Thema gehen. In weiteren Artikeln werden wir uns mit der Verwendbarkeit von Methoden der künstlichen Intelligenz in der Praxis genauer auseinandersetzen sowie auch mit der Frage, wie man solche Methoden prüfen kann, aber auch ein Grundverständnis einiger ausgewählter Methoden entwickeln.
Eine mögliche Definition von künstlicher Intelligenz findet sich auf Wikipedia:
„Künstliche Intelligenz ist ein Teilbereich der Informatik, welcher sich mit der Automatisierung intelligenten Verhaltens befasst.“
Leider hat diese Definition ein, wie ich finde, großes Problem: Wann klassifizieren wir Verhalten als intelligent? Jeder, der Siri in seinen Anfängen benutzt hat, wird sicher zustimmen, dass Siri alles andere als intelligent gewesen ist. Trotzdem wird dieser Begriff in der Wissenschaft und Wirtschaft benutzt.

Entscheidungen zu treffen, (große) Datenmengen zu klassifizieren, in Echtzeit Risikobewertungen vorzunehmen – all das sind mögliche Anwendungsbereiche von künstlicher Intelligenz. Aber auch Chatbots oder die Handschriftenerkennung sowie deren Umwandlung in maschinengeschriebenen Text sind einige Anwendungsfelder. Auch zur Aufdeckung von Fraud lassen sich heute bereits künstliche neuronale Netze verwenden.
Maschinelles Lernen hingegen ist nur ein Teilbereich der künstlichen Intelligenz, allerdings mit einer der präsentesten (viele Unternehmen wollen Methoden des maschinellen Lernens in ihrer Wertschöpfungskette gewinnbringend einsetzen, wissen aber nicht wie), daher ist eine saubere Definition auch hier sehr wichtig. Dazu findet sich ebenfalls eine mögliche Definition auf Wikipedia:
„Maschinelles Lernen (Machine Learning, ML) ist ein Zweig der angewandten Mathematik und Informatik, bei der Algorithmen versuchen, mittels Daten Muster und Regeln zu erkennen und diese auf neue Datensätze anzuwenden.“
Diese Algorithmen sind, wie man schon der obigen Definition entnehmen kann, auf die Lieferung von Daten angewiesen. Genau hier liegt meistens die Schwierigkeit vieler Machine-Learning-Ansätze. Denn möglichst viele und „qualitativ hochwertige“ Daten zu bekommen, ist ein großes Problem.
Wo kommen diese Algorithmen zum Einsatz? Es gibt unzählige Beispiele. Viele Klassifikations- und Vorhersagemethoden verwenden Machine-Learning-Ansätze, wie z.B. Risikoberechnungen in Banken. Scoring-Systeme lassen sich auch mithilfe von Machine-Learning-Ansätzen verbessern. Ein klassisches Beispiel dafür ist der Schufa-Score, der zur Bewertung der Bonität herangezogen wird.
Gerade bei der Schufa ist es aber so, dass die bereitgestellte Datenmenge sehr groß ist, weil viele Unternehmen mit der Schufa zusammenarbeiten. Daher fällt es der Schufa (wahrscheinlich) auch leicht, schnell eine präzise Aussage darüber zu treffen, ob die Bonität von Endkunden gut oder schlecht ist. Leider findet sich hier ein sehr großes Problem von Machine-Learning-Methoden wieder: Auch wenn die Datenlage nach DS-GVO für jeden einsehbar ist, so ist die Entscheidung für die Einstufung nicht klar. Aber auch dazu später mehr.
Deep Learning: Anlehnung an das menschliche Gehirn
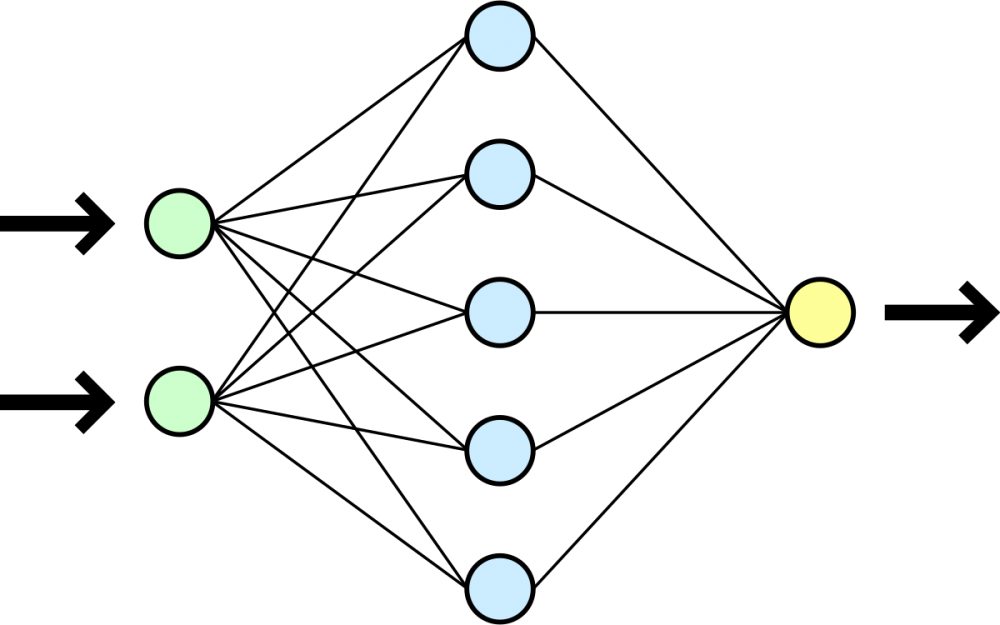
Der dritte Begriff, der in diesem Zusammenhang häufig fällt, ist Deep Learning. Dies ist ein Teilgebiet von Machine Learning und befasst sich u.a. mit der Theorie der künstlichen neuronalen Netze (kNN). Ein künstliches neuronales Netz ist (stark vereinfacht) ein gerichteter und gewichteter Graph mit mindestens einer Quelle und mindestens einer Senke. Dazwischen befinden sich viele, weitere Knoten, die man auch „hidden layer“ nennt. Das untere Bild ist eine vereinfachte Darstellung eines solchen Netzes. Die grünen Knoten sind die Quellen des Graphen, die den Input bilden. Alle Kanten haben eine Bewertung, mathematisch auch Gewichte genannt. Die blauen Knoten sind das erste hidden layer des künstlichen neuronalen Netzes, diese werden unterschiedlich stark aktiviert und geben dann ihr Signal zu dem gelben Knoten weiter. Dieser ist eine Senke oder auch der Output des künstlichen neuronalen Netzes.
{kind=link}
Die Knoten im hidden layer werden alle durch eine Aktivierungsfunktion, ähnlich wie Neuronen im menschlichen Gehirn, verschieden stark aktiviert und führen dann zu einem Gesamtergebnis.
Fachwissenschaftlich sind Deep-Learning-Methoden, meiner Meinung nach, am schwierigsten in Unternehmen umzusetzen, denn:
Sie benötigen sehr viele, gut aufbereitete Daten zum Trainieren.
Die Kosten für die dafür benötigte Hardware sind immens hoch.
Die reine Trainingszeit ist sehr lang.
Auch wenn eine mathematische Beschreibung nicht schwierig aussieht, so kann die richtige Wahl der Anzahl der Knoten,
deren Aktivierungsfunktionen etc., mathematisch beliebig anspruchsvoll werden.
Für das Verständnis, wie ein künstliches neuronales Netz lernt, ist ein mathematischer Background absolut notwendig. (Stichwort: (Pseudo-)gradientenverfahren, Backpropagation)
Was lernen wir also aus unseren Überlegungen: Ein erstes Fazit
Methoden der künstlichen Intelligenz sind mehr als reine Buzzwords, sie finden Einzug in Unternehmen jeglicher Größe. Meiner Meinung nach fehlt es den Unternehmen aber zunehmend an Verständnis, Funktionsweise und der Einschätzung des Arbeitsaufwands solcher Methoden. Für die Konzipierung solcher Methoden sollten immer fachlich geschulte Menschen zur Rate gezogen werden (Data Scientists, Mathematiker*innen etc.), um auch die Ergebnisse zu bekommen, die man erwartet.
Außerdem sind qualitativ hochwertige Daten nicht nur hilfreich, sondern absolut notwendig, um entsprechende Methoden effektiv zu entwickeln.
In den nachfolgenden zwei Artikeln der Reihe möchte ich mit Ihnen das CRISP-DM Rahmenwerk besprechen und dies an einem Business Case vorführen. Danach werden wir weitere KI-Methoden an Beispielen kennenlernen und uns am Ende der Reihe mit der Nachvollziehbarkeit und dem Audit von KI-Methoden befassen.
Business Case zur künstlichen Intelligenz – Teil 1 (hier geht es zu dem Beitrag)