
Im ersten Teil habe ich Ihnen einen Anwendungsfall einer Text-Mining basierten Methode zur Analyse von Buchungsbelegen vorgestellt und dabei kurz angerissen, dass ein vorhandener Text vor der Analyse gut vorbereitet sein will.
In diesem Artikel gehe ich genauer auf diese Vorbereitung, das sogenannte Preprocessing, ein und stelle Ihnen die typische Vorgehensweise vor. Die dabei gewählte Entwicklungsumgebung ist das R Studio unter der Programmiersprache R. Die Grundlage für diese Auswertung ist der vorangegangene Blogeintrag meines Kollegen Béla Maaß.
Textbasierte Daten können uns in diversen Formaten vorliegen. Moderne Entwicklungsumgebungen bieten einfache Möglichkeiten z.B. CSV-, DOCX-, JSON-, PDF-, TXT-, XLSX-Dateien zu importieren.
Liegen die Dokumente gedruckt oder gar handschriftlich vor, so können OCR-Tools (Optical Character Recognition) diese sehr zuverlässig in ein gängiges Format überführen. Damit man nicht per Hand Inhalte von Internetseiten kopieren muss, benutzt man so genannte „Web Scraper“, hier leistet das R-Paket „RVEST“ gute Dienste.
Preprocessing von textbasierten Dokumenten durchführen
Wenn ich die Hürde des Imports der Daten gemeistert habe, verfolge ich sehr gerne den Ansatz des „Tidy Text“-Formats. Dieses wird so definiert, dass der Input in eine Tabelle mit einem Wort pro Reihe überführt wird. Dieses Format kann man auch auf mehrere Worte pro Reihe überführen, die so genannten „n-Grams“ – dazu später mehr. Der Vorteil in dieser Darstellung der Daten liegt darin, dass sie sich besonders gut verarbeiten lassen. Darunter fällt z.B. das Zählen, Gruppieren, Filtern.
Die Bibliothek DPLYR bricht durch die Funktion Tibble den Text auf Zeilen runter. Diese Funktion ermöglicht auch die Selektion des zu bearbeitenden Texts.

Die Bibliothek TIDYTEXT löst nun durch den Aufruf unnest_tokens, die einzelnen Wörter aus dem Satz und speichert dieses in das bereits genannte „ein Wort pro Reihe“-Format. Abhängig von der Länge des Inputs zeigt der Editor der Entwicklungsumgebung nur einen Ausschnitt der verarbeiteten Daten.

Diese Tabelle enthält nun jedes Wort der Eingabe und es ist ebenfalls gewollt, dass sich Begriffe doppeln. Schließlich lebt die statistische Analyse von relativen und absoluten Häufigkeiten. Je nach Anwendungsgebiet bin ich daran interessiert Zahlenwerte zu behalten, doch in diesem Fall konzentrieren wir uns auf reinen Text. Nach dem Entfernen von Zahlen widmet man sich der Filterung von so genannten „Stop-Words“. Diese sind nichts anderes als Füllwörter, die in häufiger Frequenz in einem Text vorkommen und keine Relevanz für die Erfassung des Dokumenteninhalts haben. Für diesen Zweck gibt es ein für die gängigsten Sprachen passendes Paket, das ein Stop-Word Verzeichnis bereitstellt. Im Laufe der Zeit wird jedoch jeder Anwender eine auf seine Bedürfnisse abgestimmte Sammlung solcher Listen vervollständigen.

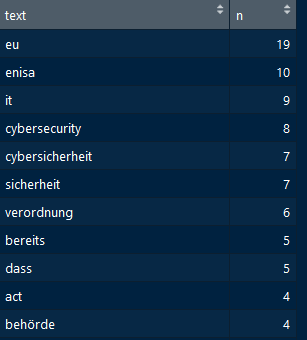
Daraus resultiert eine Liste aus Begriffen, die absteigend nach ihrem Vorkommen sortiert sind. In diesem Beispiel wird schnell die Wichtigkeit einer individuellen Sammlung an Füllwörtern deutlich. Es sind weiterhin Begriffe wie „bereits“ oder „dass“ in der Liste der meistgenutzten Wörter. Dieses Preprocessing stellt die Basis für eine weitere Verarbeitung in vielen spannenden Anwendungen dar. Durch eine Visualisierung als Wordcloud haben wir nun ohne großen Aufwand die Kernthemen meines Kollegen extrahiert und einen Einstieg in das Thema des Topic-Modeling gemacht.

Sollten Sie also etwas Ordnung in Ihre Ansammlung von unstrukturiert abgelegten Dokumenten bringen, empfehle ich den Einsatz von Textmining. In meinem nächsten Blogartikel gehe ich auf die Grundlagen des Topic Modeling ein.