
Eine Analyse qualitativer Risikomodelle zwischen Aussagekraft und Aufwand
Dieser Beitrag ergänzt und vertieft den Fachartikel der „Zeitschrift Interne Revision“ (ZIR) von Prof. Dr. Andrè Heerlein und Hans-Willi Jackmuth zur risikoorientierten Revisionsplanung (erscheint voraussichtlich in Ausgabe 02/2026). Auf Basis der im Artikel dargestellten Konzepte werden Bewertungsmodelle, Risikokennzahlen und deren praktische Anwendung technologisch weiter ausgeführt. Die Umsetzung in Power Query und SQL zeigt, wie sich Transparenz, Nachvollziehbarkeit und Vergleichbarkeit von Revisionsplanungen datenbasiert überprüfen lassen. Dazu werden alle Datenmodelle zum Download zur Verfügung gestellt. Auf Basis der im Artikel dargestellten Konzepte werden Bewertungsmodelle, Risikokennzahlen und deren praktische Anwendung technologisch weiter ausgeführt. Die Umsetzung in Power Query und SQL zeigt, wie sich Transparenz, Nachvollziehbarkeit und Vergleichbarkeit von Revisionsplanungen datenbasiert überprüfen lassen. Dazu werden alle Datenmodelle zum Download zur Verfügung gestellt.
Als Einleitung wiederholend eine Zusammenfassung der Kernaussagen des ZIR-Artikels. (Nicht technische) Beschreibungen und Tabellen des ZIR-Artikels wurden bewusst zum besseren Verständnis übernommen:
Die risikoorientierte Revisionsplanung bildet das Fundament für eine strategische und zielgerichtete Auswahl von Prüfobjekten. Sie ermöglicht, Risiken frühzeitig zu erkennen und die Revisionsaktivitäten an den wichtigsten Unternehmenszielen auszurichten.
Die Global Internal Audit Standards (GIAS) definieren den professionellen Rahmen der Internen Revision. Sie fordern eine risikoorientierte Prüfungsplanung, die regelmäßig angepasst und mit der Unternehmensstrategie abgestimmt wird, um Governance und Ressourcen optimal einzubinden.
Ziel ist die Fokussierung der Prüfungen auf die risikoreichsten Bereiche, um Wirksamkeit und Effizienz zu erhöhen. Die Planung muss dynamisch erfolgen, Managementziele berücksichtigen und formale Übersteuerung vermeiden.
Risikokennzahlen schaffen Transparenz und Vergleichbarkeit zwischen Prüfobjekten. Sie bilden die Grundlage für eine objektive Priorisierung von Risiken und fördern eine konsistente Kommunikation innerhalb der Organisation.
Bewertungsmodelle übersetzen Risikokennzahlen in vergleichbare Scores. Sie bilden die Basis für objektive Entscheidungen und können interne sowie externe Datenquellen integrieren. Die Berechnung erfolgt meist über mehrstufige Skalen, die Transparenz und Nachvollziehbarkeit gewährleisten. Skalenwahl und Modellkomplexität sollen praktikabel bleiben und Verzerrungen vermeiden.
Implementierung und Funktionsweise in Power Query
Ziel dieses Artikels ist es, die Rechenmethodik auf Basis von MS Power Query nachvollziehbar zu verdeutlichen, ohne eine inhaltliche Vorfestlegung vorzunehmen. Die einzelnen Parameter, ihre Einschränkungen sowie die resultierenden Auswertungen werden im Folgenden beschrieben.
Die Installation von Power Query erfolgt standardmäßig in Microsoft Excel (ab Version 2016 integriert) und ist auch in Power BI nativ verfügbar. Über den Power Query Editor können Datenquellen verbunden, transformiert und mit M-Code verarbeitet werden.
Die entwickelte Funktion erzeugt alle möglichen Kombinationen von Fragen und Antwortwerten in Form einer Grundgesamtheit, berechnet einen gewichteten Score und sortiert die Ergebnisse nach Relevanz. Die Konfiguration umfasst:
- Definition von Fragen und Antwortwerten
- Zuordnung von Gewichtungen
- Berechnung des Scores (Antwort × Gewichtung)
- Aggregation und Sortierung
- Analyse der Trennschärfe.
Diese Methode erlaubt eine flexible Anpassung an unterschiedliche Eingangsparameter und unterstützt die mathematische Auswertung der Priorisierung von Prüfobjekten. Sie bietet damit eine nachvollziehbare Grundlage für die risikoorientierte Prüfungsplanung und kann ohne komplexe Softwarelösungen (in Standard MS Excel) umgesetzt werden.
Aus Sicherheitsgründen haben wir auf einen Einsatz von Schaltflächen mit VBA-Coding verzichtet, damit das Modell bei Bedarf in allen Netzwerken nachvollzogen werden kann. Es sind jeweils die einzelnen Teilergebnisse (wenn von der Datengröße her materialisierbar – max. 400.000 Zeilen eingestellt) im Modell vorhanden, die Blätter sind aber ausgeblendet. Ebenso liegt auf den Eingabeblättern ein Pseudo-Blattschutz, der mit einem leeren Passwort aufgehoben werden kann. Alle Programmierungen in PowerQuery sind frei zugänglich und im Quelltext ausführlich dokumentiert.
Dokumentation der Funktionsweise an einem Beispiel
Wir haben in dem Tool aus unserem aktuellen Projekt zur „Prüfung des Internen Revisionssystems“ die konkreten Daten eingegeben. Das Szenario umfasst von der Größe her eine Logik für rund 60 Prüfer:Innen, wobei das angewandte Risikomodell aus Mandantenschutzgründen nur mit Daten, nicht aber mit den Inhalten dargestellt wird. Die Abbildung dieses Risikomodells erfolgt letztendlich in einer am Markt gängigen Standard-Auditsoftware.
Die Softwarekomponenten finden Sie hier
Ggf. Hilfestellung bei der Installation
Vollständig lauffähige Exceldatei
Sämtliche PowerQuery Programmierungen zum Laden und Weiterentwickeln
- qryAggregation.txt
- qryFragenraster.txt
- qryGesamt.txt
- qryGewichtung.txt
- qryKombinationen.txt
- qryKreuztabelle.txt
Die Parametrisierung erfolgt im konkreten Fall auf Basis folgender Daten:
- Es wird ein Modell mit insgesamt 6 Fragen angelegt.
- Die einzelnen Fragen verfügen über unterschiedliche Gewichtungen.
- Prinzipiell sind 5 Antwortmöglichkeiten vorgesehen.Die Antworten haben entsprechende Lücken in den Score-Werten.

Sofern Sie weder Gewichtungen noch Antwortskalen mit Lücken benutzen wollen, können Sie die nächsten Schritte überspringen:
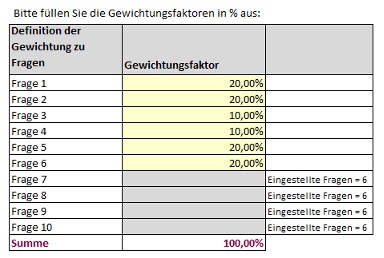
Die Masken sind so geschaltet, dass einerseits die hellgelben Felder Eingabemöglichkeiten (i.d.R. über Dropdowns) darstellen, andererseits auch interaktiv entsprechende Kommentierungen oder Ausblendungen erscheinen.
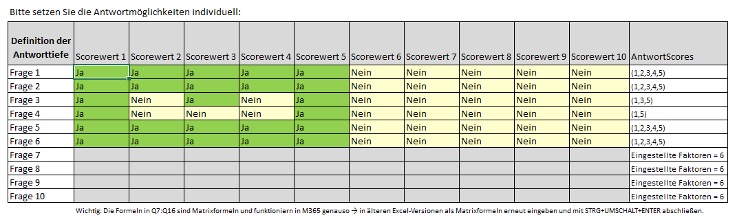
In diesem Modell werden – analog zu den Kundenanforderungen – die Frage 3 mit einer vereinfachten ABC-Analyse (A=1, B=3, C=5) und die Frage 4 mit einer Ja/Nein-Methodik (negatives Ereignis aufgetreten - Nein = 1, Ja = 5) genutzt, auch um die flexiblen Möglichkeiten zu demonstrieren.
Um das Modell durchrechnen zu lassen, benutzen Sie bitte den Weg Reiter: Daten › alle aktualisieren:

Als Ergebnis erhalten Sie in Gesamt (bitte je nach eingestellter Komplexität die Berechnung abwarten, diese sollte unter einer Minute liegen) folgende Informationen:
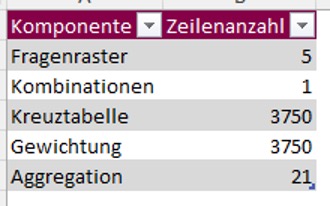
Es ergeben sich aus den im Beispiel 3750 durchgerechneten Kombinationsmöglichkeiten lediglich 21 Risikokennzahlen in der Aggregation, die zu Abgrenzungen herangezogen werden können, um eine Trennschärfe der Bewertung zu erzeugen. Das bedeutet, das für Planungszwecke beispielsweise auf 3 Jahre verteilt auch nur 21 Prüfungstermine zur Verfügung stehen!
Die Ergebnisse mit genauen Stückzahlen sowie mit einer fiktiven Betrachtung auf hochgerechnet 100 Prüfobjekte kann der Tabelle Aggregation entnommen werden:
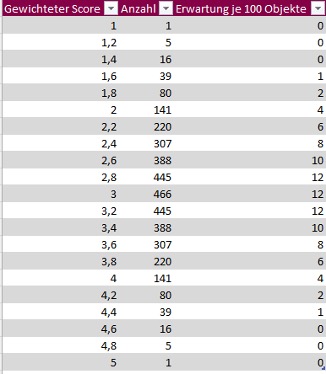
Zusätzlich werden die Daten nochmals optisch aufbereitet:
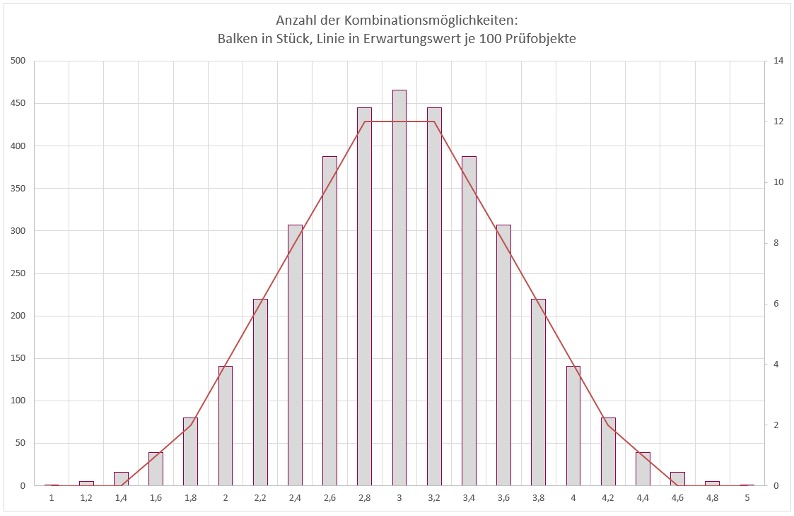
Das Beispiel zeigt deutlich, dass das aktuell eingestellte Modell nur eine (zu) geringe Trennschärfe besitzt.
Im betrachteten Segment der Grundgesamtheit – also dort, wo 10 oder mehr potenzielle Treffer pro 100 Objekte auftreten (entspricht Prüfungen mit ähnlicher Risikokennzahl und damit vergleichbarem Steuerungstermin) – befinden sich insgesamt 56 Prüfungen. Diese verteilen sich auf fünf Gruppen mit jeweils 10, 12, 12, 12 und 10 Prüfungen.
Das bedeutet: Es entstehen „Klumpenrisiken“ auf Terminen und die eigentlich gewünschte Priorisierung und flächige Verteilung der Prüfungen lässt sich nur unzureichend ableiten.
Codenachweis
Der Code ist vollständig offen in dem Exceltool einsehbar. Er wurde jeweils je Funktionsblock einleitend mit einer Zeile kommentiert, wie es in PQ den „Best Practices“ entspricht.
Da der Code in MS EXCEL PowerQuery relativ leicht nach jedem Schritt debuggt werden kann, kann man bei Bedarf schrittweise die einzelnen Abfragen analysieren.
Fazit PowerQuery
Die dargestellte Umsetzung in MS Excel Power Query erlaubt eine schrittweise Analyse und ein transparentes Debugging jeder einzelnen Abfrage. Durch die klare Trennung der Transformationsschritte kann die Logik jederzeit nachvollzogen, angepasst und validiert werden.
Bei stark steigender Kombinatorik und wachsender Datenmenge stößt der Ansatz jedoch naturgemäß an Performance-Grenzen. Diese Überlegungen bilden die Grundlage für die im nächsten Abschnitt dargestellte SQL-basierte Analyse.